Archive - Historical Articles
You are viewing records from 02/26/2004 19:24:05 to 02/19/2005 15:19:57. I'll be adding support for selecting a date range in future.
http://me.sphere.pl/indexen.htm
MoonEdit is a multi user text editor, it lets two (or more) people simultaneously edit a single file, with multiple cursors, entry points and near real time collaboration.
I've been waiting for something like this for a while, after posting about it first, then a year or two later seeing SubEthaEdit for the Mac. Hopefully someone (http://docsynch.sourceforge.net/) will come up with a plugin for Visual Studio.
(Links curtesy of ntk.net)
PermalinkI've noticed some google oddness, a lot of sites have suddenly dropped quite low in rankings. My DeveloperFusion profile page is now higher than my CV and this site!
Robert Scoble is now the SECOND Robert. No other search engine places THAT much weight on the Scobleizer.
And when searching for my current employer, Capita, a partner of theirs comes up first!
I have been trusting gigablast and even the new MSN search more than google recently, and I can't quite be sure what google have done to skew their current index.
(At least, on the search engine front. I am very impressed with some of google's current projects.)
Permalink 1 Comments[CodeBlog] Simple Object Relation Mapping with Reflectio - by simon at Sun, 06 Feb 2005 12:10:12 GMT
This is some code I wrote a little while back as an example OR mapper. When inheriting from BaseDataDynamicEntity you can use the attribute [DataDynamic(“Name”)] to indicate the field name in the database and then use the class below to fetch data from the database or update it with any changes.
This is just an example though and doesn’t do the updating – but instead returns an array of string that can be used to look at what’s in the object now. Return a set of SqlParameter’s and plug it into a stored procedure for a working example.
public abstract class BaseDataDynamicEntity
{
/// <summary>
/// An attribute to use to work out which properties have names that are in the database
/// </summary>
public class DataDynamic : Attribute
{
public DataDynamic(string fieldName)
{
_fieldName = fieldName;
}
/// <summary>
/// The name of the field in the database
/// </summary>
public string FieldName
{
get
{
return _fieldName;
}
}
private string _fieldName = "";
}
/// <summary>
/// Return a set of properties on this class as a demonstration of what is possible
/// </summary>
/// <returns></returns>
public string[] ListDataProperties()
{
Type t = this.GetType();
PropertyInfo[] p = t.GetProperties();
ArrayList properties = new ArrayList();
foreach (PropertyInfo pi in p)
{
if (pi.IsDefined(typeof(DataDynamic), true))
{
properties.Add(pi.Name+": "+pi.GetValue(this, null).ToString()); //could instead write these out to some parameters.
}
}
string[] values = new string[properties.Count];
properties.CopyTo(values);
return values;
}
/// <summary>
/// Given an SqlDataReader from ExecuteReader, fetch a set of data and use it to fill the child objects properties
/// </summary>
/// <param name="dr"></param>
public void SetDataProperties(SqlDataReader dr)
{
while (dr.Read())
{
for (int i = 0; i<dr.FieldCount; i++)
{
setProperty(dr.GetName(i), dr.GetValue(i));
}
}
dr.Close();
}
private void setProperty(string name, object data)
{
Type t = this.GetType();
PropertyInfo[] p = t.GetProperties();
foreach (PropertyInfo pi in p)
{
if (pi.IsDefined(typeof(DataDynamic), true)&&pi.CanWrite)
{
object[] fields = pi.GetCustomAttributes(typeof(DataDynamic), true);
foreach (DataDynamic d in fields)
{
if (d.FieldName == name)
{
pi.SetValue(this, data, null);
}
}
}
}
}
}
And to use this, you do something like:
public class NewsArticle: BaseDataDynamicEntity
{
private int _id = 5;
/// <summary>
/// The Id in the database
/// </summary>
[DataDynamic("id")]
public int Id
{
get
{
return _id;
}
set
{
_id = value;
}
}
private string _name = "Demo object";
/// <summary>
/// The name in the database
/// </summary>
[DataDynamic("subject")]
public string Name
{
get
{
return _name;
}
set
{
_name = value;
}
}
}
Which makes populating it as easy as:
SqlConnection sq = new SqlConnection("Data Source=(local);InitialCatalog=nullifydb;Integrated Security=SSPI;");
sq.Open();
SqlCommand sc = sq.CreateCommand();
sc.CommandText = "SELECT TOP 1 * FROM newsarticle";
NewsArticle n = new NewsArticle();
n.SetDataProperties(sc.ExecuteReader());
sq.Close();
Obviously this is just an example, and you would want to use a DAL of some sort to do the data extraction, but integrating the DAL with the above technique should be fairly easy.
PermalinkThis is something I posted to a mailing list in response to a question, but since posting it I've also been asked some questions which it answers - so, here is a VERY quick rundown of DNS:
> I basically need:
>
> (a) An overview of all the bits in the process – so I know I haven’t
> missed something obvious!
DNS is a tiered, cached method of querying some form of data, not necessarily a name, not necessarily an IP, not necessarily a text record, location, what the router for a network is, what the Kerberos/LDAP servers for a domain are, etc.
It uses the format:
Name dot
To distinguish a part, therefore (taking my own domain as an example) it is not really:
Nullify.net
But instead:
Nullify.net.
However the last dot is commonly left off for convenience incorrectly. One or more domains controlled as a single entity on a server is called a 'zone'.
The bits that make up DNS from a practical standpoint consist of:
- A resolver
- A cache
- An authoritative server
The resolver is what exists on every persons computer, and on the ISP's nameservers along with a cache. The resolver requests from the default DNS servers for the current dns 'zone' any desired records - in the case of a site that is in the root zone, or wants to query the root set of DNS servers there are a set of root servers, located at root-servers.net. These can be extracted using dig, and have always stayed at the same IP - although one of these servers got a new multicast IP a short while ago. Once a result (or NXDOMAIN, indicating there isn't a result) is retrieved - it is stored in the cache along with it's time to live (ttl).
The cache is the reason a small number of servers can support the whole Internet (obviously there's a lot behind the scenes, but the point still holds). The vast majority of traffic is handled by the caches at every stage. There will commonly be as many as four caches between an authoritative nameserver and a client. The TTL maintains how long these hold a record of those results, and this is why DNS changes take so long. The exact same cache is also used on a secondary nameserver, but rather than the TTL for records, the TTL for the zone itself is used.
An authoritative nameserver is a server that knows something itself. It responds with a particular record for a particular domain - assuming anyone asks it. There are both master and slave servers - a master holds the file that actually stores the data, the slave stores it in memory and relies on the TTL for the zone itself to decide how long it is authoritative. The slave uses the zones serial number to decide whether a change has been made, and refreshes every time the refresh property of the SOA record for a zone has been expired.
>
> (b) An idea of how to set up the Windows Server as the primary nameserver
> (not sure if this is a good idea)
For windows you just create a zone and create the desired records. From then on it will answer as a nameserver and can be queried by a machine looking at it as the default nameserver, or using nslookup/dig with it set as the default.
You then need to point a server on the internet for the domain you are adding a record to (say, net. Or com.!) to think it is the nameserver for a domain, and you require either an out of zone A record for it, or a glue record for it so that the IP of your own server can be resolved in order to go query it for the details of your domain!
To simplify this, for my domain I have a primary nameserver xerxes.nullify.net. at 2002:4262:b24a::4262:b24a and 66.98.178.74
This means that in order for xerxes to host nullify.net, the nameservers for net. Need to also contain both AAAA and A records for it. A records resolve to a host. (AAAA is ipv6, which you don't need to worry about yet). You should request these records are created in advance for ALL nameservers that do not already have glue records. The contact for the netblock the servers are hosted in may be contacted by some TLD providers, but net. And com. don't do this.
Once you have glue records that have propagated to all the servers for the zone they are in, you need to ask them to delegate a hostname for you - this is your domain and results in your domain being set to use your nameservers - this is an NS record, and there will be one for each nameserver that knows that domain.
>
> (c) An idea of how to configure secondary nameservers
Create a secondary zone, pointed to yourdomain.tld. - note the last dot. Then you need to make sure you secondary server has a glue record in your TLD and an A record in your domain, add an NS record to YOUR copy of the domain pointing to the nameserver, and finally have it added as an additional NS record to the TLD's servers.
>
> (d) An overview of how MX records work
An MX record is a mail exchanger record, when you send mail to a host the following happens:
- An attempt to resolve it as an A record occurs.
- An attempt to resolve it as an MX record occurs.
- Each returned MX record points to an A record that is resolved.
- Mail delivery is attempted at the A records in order of weighting.
The MX records take priority, to allow an A record to exist for a host, but that host not to receive mail.
MX records have a weighting, the lowest takes mail first, then if that is down the next highest, and so on. MX records with the same weighting are attempted randomly.
If all MX records bounce, the message is queued but eventually bounces with a failure. If there are no MX records, and no A record, the mail bounces instantly. If there is an A record, delivery is attempted and on failure, it bounces instantly.
>
> (d) An overview of Reverse DNS records (and whether I need these)
>
You do need these to deliver mail, you also need these if you wish to run a netblock, since it can be revoked by the issuer if you fail to do so.
As the owner for a netblock, you also have rights to a second domain - in in-addr.arpa.
This domain follows the reverse of an IP, so it can be followed down through the ownership chain, for example if RIPE issued you the address space 192.168.0.0/24 you would have the zone:
0.168.192.in-addr.arpa.
You could set up www here, but it wouldn't be much use. More use would be to set up a PTR record for your SMTP server, which is at 192.168.0.8:
8.0.168.192 PTR mymail.mydomain.tld.
Note that when working with DNS you really do need the final dot, otherwise it'll exist in your current domain. This is the common cause of lots of problems like cname's not resolving correctly and instead trying to go to mymail.mydomain.tld.mydomain.tld.
A cname is an alias.
------
Records you need to know about are:
SOA - the actual domain as it is stored on your system.
A - a hostname to IP
PTR - an ip to hostname
SVR - a common service (e.g. - ldap and Kerberos to log in to active directory in a domain)
MX - mail exchanger
CNAME - an alias, or common name
TEXT - information or other details
You can explore from the client side and test everything is working by using nslookup.
To use nslookup, open a command prompt, define what record type you want, and type the name of the record.
For example:
C:\>nslookup
Default Server: vex.nullify.net
Address: 192.168.0.5
> set type=a
> xerxes
Server: vex.nullify.net
Address: 192.168.0.5
Name: xerxes.nullify.net
Address: 66.98.178.74
> set type=ns
> nullify.net.
Server: vex.nullify.net
Address: 192.168.0.5
nullify.net nameserver = ns1.twisted4life.com
nullify.net nameserver = queeg.nullify.net
nullify.net nameserver = xerxes.nullify.net
queeg.nullify.net internet address = 66.45.233.165
xerxes.nullify.net internet address = 66.98.178.74
xerxes.nullify.net AAAA IPv6 address = 2002:4262:b24a::4262:b24a
> set type=mx
> nullify.net
Server: vex.nullify.net
Address: 192.168.0.5
nullify.net MX preference = 20, mail exchanger = xerxes.nullify.net
nullify.net MX preference = 30, mail exchanger = queeg.nullify.net
nullify.net MX preference = 10, mail exchanger = firewall.nullify.net
nullify.net nameserver = ns1.twisted4life.com
nullify.net nameserver = queeg.nullify.net
nullify.net nameserver = xerxes.nullify.net
firewall.nullify.net internet address = 81.109.199.173
xerxes.nullify.net internet address = 66.98.178.74
xerxes.nullify.net AAAA IPv6 address = 2002:4262:b24a::4262:b24a
queeg.nullify.net internet address = 66.45.233.165
>
Feel free to use my domain to explore it if you want, it (should be) set up correctly, and everything is public info anyway. http://www.demon.net/toolkit/internettools/ contains some useful tools to test your domain from outside your own network if you don't have access to an external machine.
Exploring from the client side gives a good idea what the server side setup will need to be.
Permalink 2 CommentsI don't normally talk about things like the Tsunami, or September 11. I let others who are much better qualified or more descriptive cover them and try not to clutter the net with more useless content, however with the deathtoll officially passing 125,000 confirmed dead - I have just one thing to say:

I've had IPv6 in testing on xerxes.nullify.net (in Texas, US) for some time as xerxes.ipv6.nullify.net but have now finally enabled it on the main hostname since it has been stable and worked reliably. I've also got it working from home (Surrey, UK) and am working on queeg.nullify.net (now New Jersey, US).
If anyone has any problems viewing anything please let me know.
PermalinkYou can do this using the OPENROWSET function in MS SQL Server, so:
SELECT * FROM OPENROWSET('MSDASQL', 'ConnectionString', 'SELECT * FROM mytable')
Which is great in a view for data consolidation - but even better is to remove the need for a connection string by connecting just once!
You can do this using sp_addlinkedserver and sp_addlinkedsrvlogin. Requirements will change depending on what you want to connect to - if you need help with a particular one feel free to e-mail me.
You can then simply use the new 'server' you just set up as so:
SELECT * FROM OPENQUERY(servername, 'SELECT * FROM mytable')
PermalinkHave you ever wondered how to check if a number is an integer in C#? Wondered why Convert.ToInt32() surrounded by a try catch is so slow? Well, this article is for you then.
As everyone should know, catching an exception is an extremely time consuming task, but there's no obvious way to check if a string is actually an integer. And before the visual basic people all say about Microsoft.VisualBasic.Information.IsNumeric this is actually simply a try...catch around a Convert.ToInt32 call.
Okay, so what is the performance drop incurred by using a try...catch and why should you worry?
Well, it's slow - 1000 iterations of try...catch around a Convert.ToInt32() comes to 2515.625 ms. Programmatically that's a HORRID use of CPU time.
Some people (particularly on blogs.msdn.com's comments) have suggested that this is simply something you must incur, however due to NumberStyles (in System.Globalization) containing an entry for Integer it needn't be. We can use Double.TryParse without the risk that the double we'll be getting back will contain anything but a valid integer.
This is amazingly faster - 100,000 (100 times more than with a try...catch!) worst case scenarios come to a grand total of 46.875 ms of cpu time used up. A much better overhead.
It returns True if the string was an integer and false if not - altering the value of the double passed into it as an out parameter to be the correct amount if it succeeds. Note that the if statements are just there to confuse the compiler so it doesn't optimise out the whole contents of each for loop.
Here's an example application (sorry, no walkthrough as I have too little time, but this should be simple enough!):
using
System;using
System.Globalization;namespace
BlogExamples.IntegerValidation{
class IntegerValidator{
static void Main(string[] args){
Console.WriteLine(
"Comparison of speed of try..catch checking of integers");Console.WriteLine(
"1000 iterations of try...catch Convert.ToInt32()");DateTime before = DateTime.Now;
for (int i=0; i<1000; i++){
try{
int t = Convert.ToInt32("testing"); if (t>1000){
Console.WriteLine(
"Optimisation cheating");}
}
catch{
}
}
TimeSpan duration = DateTime.Now - before;
Console.WriteLine(duration.TotalMilliseconds+
" ms total");CultureInfo MyCultureInfo =
new CultureInfo("en-GB");Console.WriteLine(
"100000 iterations of Double.TryParse() (to be fair!)");DateTime before2 = DateTime.Now;
for (int i=0; i<100000; i++){
double d = 0;Double.TryParse(
"testing", System.Globalization.NumberStyles.Integer, MyCultureInfo, out d); if (d>1000){
Console.WriteLine(
"Optimisation cheating");}
}
TimeSpan duration2 = DateTime.Now - before2;
Console.WriteLine(duration2.TotalMilliseconds+
" ms total");Console.ReadLine();
}
}
}
Which when run on my machine reports the following:
Comparison of speed of try..catch checking of integers
1000 iterations of try...catch Convert.ToInt32()
2515.625 ms total
100000 iterations of Double.TryParse() (to be fair!)
46.875 ms total
Yes, I know I haven't posted anything in over a month - I don't really have anything useful or relevant to post now either.
This is the unfortunate result of actually doing work rather than blogging, which has come about due to full time employment once again!
I'll possibly post something later on to do with C# and finding out if a string is an integer without using try...catch (it's not as simple as it sounds, no, that VB isnumeric thingy uses a try...catch!).
PermalinkThen maybe you have something in your most recently used list that's needing a network lookup. UNC pathnames were causing the problem for me.
You can clear your MRU lists by exiting visual studio, then opening registry editor and deleting the contents of the keys FileMRUList and ProjectMRUList in HKEY_CURRENT_USER\Software\Microsoft\VisualStudio\7.1\
PermalinkIf your web service (or one you're consuming) is playing up (405 Gateway timeouts, other odd behaviour) when being debugged, maybe it's the VsDebuggerCausalityData header - it's a huge string seemingly mostly filled with AAAA!
You can disable this from being sent by adding the following in your App.Config file:
<configuration>
<system.diagnostics>
<switches>
<add name="Remote.Disable" value="1">
</switches>
</system.diagnostics>
</configuration>
This will disable the debugger from getting involved with the badly configured server (the VS header is within the HTTP specs upper limit on size).
This has been annoying me for at least the past day trying to talk to a partner of works web service!
PermalinkSo for my 21st birthday I figured I'd treat myself to a new computer (which is missing a graphics card for the moment, so I have to use it over terminal services :-/) - it's spectacular...
Whilst most machines get ~1.7GB/s bandwidth to the system memory, and the latest Intel Xeo's get 2.6GB/s - with a NUMA enabled copy of Windows XP (ie - it has service pack 2) I get a nice 10GB/s. And no, I'm not mixing up Gb and GB! I think this is the fastest result for the SiSoft Sandra benchmark I've seen out there without overclocking... Actually, even with overclocking I think it's the fastest!
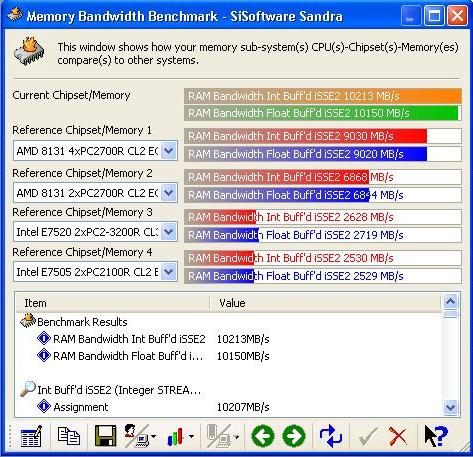
If you ever want performance, dual Opteron (AMD64 server CPU's) are definetely it when mixed with a good motherboard like the DK8N from Iwill! I only had some minor problems with the Western Digital hard disks and trying to use both raid controllers at once.
(Thanks has to go out to http://www.rainbow-it.co.uk/ who managed to source all the components and have provided simply the BEST customer service - even when I wanted particularly special components - they beat Dabs in shipping time by months...)
PermalinkWhilst I wait for someone to get back to me about something, I figured I'd quickly post about something that initially confused me about server controls on ASP.NET so that there's at least SOME new content!
ASP.NET server controls are simple components that run on the server and allow you to refactor a quantity of your sites code (such as a menubar) into a seperate module that is both reusable like a user control, and dynamic. A server control can run code and also allows you to drag and drop it onto your pages. A server control also has the ability to render itself at design time, so no more silly grey boxes - but rather a WYSIWYG situation (once it's built)!
So, once you've created a server control using VS.NET 2003 (or your choice of IDE!) you can easily add to the render override with something simple:
output.Write("<div class=\"mycssclass\">Hi there!</div>");
Any HTML will work, and all is fine if you just want to insert static HTML.
But what if you want to use the server control as if it were an ASP.NET application - or winforms control?
You know, so you can click a link or a button and it'll do 'something' and remember that state.
To do this you will need an event handler attached to a control. So you create an instance of a control and delegate its event to the handler! In winforms this is extremely easy, but in ASP.NET making it work right requires you set it all up early enough in your code! This is the gotcha that had me stuck for a couple of hours when I first learnt it. I did it in the render override.
Instead, change your render override to read as follows:
protected override void Render(HtmlTextWriter output){
output.Write("<div class=\"myCSSClass\">");
this.RenderContents(output);
output.Write("</div>");
}
This will allow you to render the controls at the right time and yet create them early enough - which will let ASP.NET create the eventhandler and wire it up for you.
Now, to create the controls that will be rendered you need to create a new override:
public LinkButton l;
protected override void OnInit(EventArgs e){
base.OnInit (e);
l = new LinkButton();
l.Text = "Click me! I'm a link that triggers an event on the server!";
l.Enabled = true;
EventArgs args = new EventArgs();
l.Click += new EventHandler(this.l_Click);
this.Controls.Add(l);
Literal br = new Literal();
br.Text = "<br />";
this.Controls.Add(br);
}
This will create two controls - which will be rendered in the render method. You can now create the event handler and any code you place in it will work! If you had created the controls in the render method itself you would have found that although they posted back to the server, they didn't call the event handler.
(Note: += means "add one of" and "base" is the WebControl you are inheriting from when creating a server control.)
A quick example event handler for those who've never done one before:
void l_Click(object sender, EventArgs e){
l.Text = "Thanks!";
} Permalink
If wbms's security is in doubt, how about using a web based msn from the horses mouth?
Microsoft's own web based msn messenger should be more reliable.
(Excuse for lack of posting: Tackling an interop issue)
PermalinkI've been asked by some friends to upload some photos of Ballard - a building at Collingwood College where I used to work (yes, the evil workplace I have thankfully left was a College!).
They are really poor quality as they are just what I managed to take using my camera phone, and were (all but one) already photos of the building from the past.
If anyone reading this wants to contribute some other photos feel free to e-mail me with them and I'll upload them. I also have a small forum for discussion by Collingwood College alumni - incedentally they have pictures of the new building that will be replacing it at the official site.
PermalinkSorry for the lack of entries, I've been pre-occupied with non-programming work things. I will be building an intranet shortly though (whether the person that mentioned it actually wants it or not since it'll keep my technical skills active - will probably actually build 'bits' similar to sharepoint if I don't choose to go that route), so should have something interesting to post in the next few weeks.
The big question is, sharepoint or code?
PermalinkThis is just google juice as an experiment - hopefully after google gets this searching for a cryptic number will lead here.
With ICQ now dead, you can contact me by e-mail from the contact section.
PermalinkDina (no url/blog yet!) mentioned wbMSN to me. I'm not sure of the security of your password if you use it, however the concept is great - it allows you to use MSN without actually being logged into the smart client so you can chat if MSN Messenger itself is blocked on your corporate network (although then it's still inadvisable ;)).
PermalinkSo, I manage to bump into an article by Sam Gentile who is complaining about SQL Express.
He complains there's no manual, docs, sample database or user interface.
I do believe there's a lack of documentation - it could do with coverage of the new features, however MSDE had no user interface, sample database or documentation. It's a royalty free, application deployable database - not SQL Server 2005 Enterprise Edition.
The product is a good year away at least! And given what has already been written in various weblog entries and comments you can get the key parts to work fine. Creating/importing a sample database is also simple enough as to be a good entry level test of the user to see if they actually should be playing with the product.
Beta means Beta, not "finished product to try out" - if will always take some effort to get the most out of a beta.
PermalinkAs of 30 June 2004 Office 2000 is no longer supported - well, there's always Microsoft extended support, but that's it - no more bugfixes or patches to be released - and even extended support only lasts till June 30 2009, when even the download site will vanish.
I'm using Office 2003 here, and very happy - particularly with Outlook and OneNote, however almost every tool has improved considerably since the 2000 version. Hopefully the next version of Office will include support for languages other than VBA so people who program in languages like C# or C++ won't have to suffer VB!
But the 2000 version was the first version that was actually reliable and didn't crash all the time on people. And for that there should be a nod of the head. My memories of 97 are that of a downright bad product (although it wasn't lacking features).
PermalinkThe new version of MS SQL Server has a cut down version, like SQL Server 2000 had (MSDE) called SQL Server Express.
The restrictions on the new version are much more sensible for deployments, as rather than being limited to a predefined amount of work they're limited to storage space and hopefully clients are not likely to set up >4GB datasets of work data without being able to afford to buy a full copy of SQL Server.
The big plus though, is that you can have a .NET assembly work INSIDE your database as if it were a stored procedure, this offers major advantages - ie - a trigger can now send an MSN message or post to a web service. And that's not touching the performance differences of code in .NET.
This is further differentiating MySQL and MS SQL, which is how I like things to be since both are excellent databases.
MySQL is the definitive victor in the price/ease of use arena for data warehousing and small applications whilst MS SQL server will be the victor in the performance/features arena for smart applications or where the data will be accessed from different systems (where stored procedures/.NET assemblies enable code reuse and advanced server side logic).
PermalinkThis one had me and google stumped for a few minutes yesterday till I remembered that dBASE isn't actually a relational database but is a flat file one.
Each file is one table, so use the file management classes in .NET to list the tables your connection string has opened!
Unfortunately there's also no way to list tables in ODBC that I can see in .NET for the moment, so if you want to use a different database format you would be better off using OLE or ADO to connect if you can.
Update: Whoops, here's the code I forgot to put in:
private OdbcConnection connection;private string dbpath;
public dBaseEasyDBConn(string path)
{
dbpath = path;
Console.Write("Opening dBASE Files...");
connection = new OdbcConnection("Driver={Microsoft dBASE Driver (*.dbf)};DriverID=277;Dbq="+path);
connection.Open();
Console.WriteLine("Done");
}
public string[] GetTables()
{
int position = 0;
string[] templist = Directory.GetFiles(dbpath, "*.dbf");
string[] filelist = new string[templist.GetLength(0)];
foreach (string s in templist)
{
filelist[position] = s.Replace(dbpath, "").Replace(".DBF", "").Replace("\\", "");
position++;
}
return filelist;
}
Permalink 1 CommentsI'm currently sitting here considering what 'acceptable performance' is in a variety of situations, ranging from databases to user interfaces, or back end control systems.
The answer in most cases is:
It changes depending on your situation.
Even what is acceptable in a real-time environment varies dramatically, for example software designed to change the course of a cruise missile would need to respond quick enough to keep up with the rate of change of terrain, whereas something monitoring the change of temperature in a green house would likely not need to process the data faster than once every ten seconds.
A database must be atomic, as soon as you commit a transaction the data MUST exist in the database, but with concurrent connections and multiple physical CPU's this is clearly impossible without the database working sequentially - so acceptable performance in this case is "fast enough that nobody notices, but not fast enough to slow down total performance".
However, there is one exception to it being variable depending on the task: When the user is involved.
What is acceptable performance for a user interface?
Back in the days pre-DOS and PC era people likely waited the same amount of time for applications as they do today only with fewer features. (Obviously there were some exceptions, I remember waiting 5 minutes for a word processor to load, but things evened out pretty quickly since nobody WANTED to wait that long).
Firstly, there are two things to monitor to decide on performance. How fast the application is available to be told what to do and how much you can tell it to do without actually needing to wait. There are simple answers to both.
The second one is commonly ignored by a lot of bespoke software developers, and really big players who shall remain nameless - in the education sector the key piece of software in UK schools had serious problems with concurrency, and even after a full rewrite still has problems with concurrency of use of a single application - you tell it what to do and go have a cup of tea/coffee - it might be done when you get back.
This is obviously unacceptable, and companies like Microsoft who can afford to do user studies have clearly looked at the problem - for example, how long do you wait whilst you're saving in Word? How about printing?
Correct - you don't, even if it takes a while a seperate thread is doing the actual work so there is zero delay in the user interface - you can even be typing away as it saves or prints. They don't do it everywhere, but they do do it whereever the user would have to wait a varying amount depending on the data being altered.
This ensures that Word acts speedy even with a hundred megabyte document.
The question is, would anyone be willing to wait at that point to save the development work?
Whilst the answer is 'probably not' there would be a point where people wouldn't mind word freezing - would you mind a 1/2 a second on a save? How about 2 seconds?
This brings me onto the issue of actual delay before the application is usable again. What is acceptable here?
The first delay is loading the application. This is dependant on what the user wants to do, since we don't know in advance what they want to do our user interface must APPEAR to load almost instantly so that we can shave an additional second or so of time off our REAL loading time whilst the user decides what to click or press.
The second delay is the activity of doing something with the application, and can consist of one of two things from a user perspective:
- Critical continuity activities
- Non-critical activities (note - non-critical to UI flow, not anything else)
In the case of critical activies that the UI is dependant on, obviously the user must wait - unfortunate as it is, they will appreciate that it must happen. They might not be happy, but it IS going to take time to load the document they want to look at (even if just the first page is loaded for display purposes before the rest of the data is loaded). In these cases you can try as hard as possible, but you will always cause the user to wait - sometimes a nasty amount of time.
The non-critical activies are ones that do not have to occur to leave the user interface operable. Saving is a good example, so is printing and seach and replace - although this one is commonly not implemented properly. These activities should be implemented as seperate threads, with the user able to continue with their task, or do an additional slow task at the same time to avoid any actual period where the user is twiddling their thumbs.
So, in essence the only real answer to both key areas of UI performance is THE USER WANTS IT NOW unless it HAS to take longer, and then they should be allowed to do something else at the same time!
I wish developers would take the perspective of the actual end user when writing the application. We would see a lot more multi-threaded, multiple document interface applications I'm sure.
Congratulations to Microsoft for getting it right.
PermalinkA good friend of mine and his father are doing the London Bikeathon - a 26 mile ride for Leukaemia Research.
If anyone would like to sponsor them, even a tiny token amount please donate/pledge something.
PermalinkIt seems as though Microsoft have a little competition going - and it revolves around the Visual Studio 2005 Express line of products. Note that this includes the new version of SQL Server!!
If you're like me and have been eager to get your hands on a copy of Visual Studio 2005 - this is a good way to check out some of the new features - even if most are missing from these small applications.
This is exactly the right idea and will hopefully encourage more people to use .NET!
Update: Who cares about the little bits (although they're available and you can actually download them, unlike whidbey for the moment). The almighty whidbey is ALSO in beta!
PermalinkMatt Warren over at The Wayward WebLog is seemingly in a war of... posting with those who are only posting work related stuff.
As a sign of support I'm posting a link to his blog, not that my meagre quantity of visitors will make much of a difference but you can always hope ;)
That and I'm not going to spam for his blog, it's not THAT good. Well, not yet.
So please, visit his totally irrelevant blog and read some of the good stories, gibberish, filler he's written.
PermalinkThis is a nice neat way of resizing an image, I've simplified it and de-refactored (?) it for simplicity.
Firstly, you ask for your image from the database:
SqlCommand cmd = new SqlCommand("SELECT image FROM images WHERE id=@id", connection);cmd.Parameters.Add("@id", Request.QueryString["id"]);
SqlDataReader dr = cmd.ExecuteReader();
Allocate an array of bytes to store it in temporarily:
byte
[] image = null;while (dr.Read())
{
image = (byte[])dr.GetValue(0);
}
dr.Close();
Now you have an array of bytes that contains your image, you can freely load it into a bitmap from the array:
Bitmap b = (Bitmap)Bitmap.FromStream(new MemoryStream(image));
And you can resize that bitmap easily using the overloaded bitmap constructor:
Bitmap output = new Bitmap(b, new Size(320, 240);
One resized bitmap that you can now save or send anywhere - including Response.OutputStream!
PermalinkI've added CDATA's to my rss feed to prevent the html from FreeTextBox 2.0 escaping and making my feed invalid.
I've also added photo album support to SiteBuilder, although I'm not sure what I'm going to do with it until I add security rights.
Update: I put a few of my better photos in it as a test.
PermalinkWhat has happened to me?? This used to be a staunchly anti Microsoft blog. Well, when it was tech oriented.
I think the stuff over at http://blogs.msdn.com is infectious, I've posted more programming and techie articles since reading that site. And it's all been favouring Microsoft...
Hum...
Uh oh, I might've been evangelised without realising it by Robert Scoble!!
PermalinkI just found an article at http://blogs.msdn.com/mszCool/archive/2004/06/14/155420.aspx that goes really well with my old article about using reflection to build plugins.
Basically the article covers how to change the permissions of the appdomain to allow only permitted actions - a great thing to do if you want your users to be able to build the plugins!
(Update five years later in 2009: Also I forgot all about this article and did my own example here http://www.nullify.net/ViewArticle.aspx?article=315 )
Permalink[blog] Four months of stability from Windows 2003 Server - by simon at Sat, 12 Jun 2004 10:51:36 GMT
Kudos to the guys (and gals) over at MS for making a serious contender in the server OS market - my Windows 2003 Server has been up for four months now after its teething troubles where it crashed once.
The question is, will it beat the 207 days uptime my Linux servers were on before they got replaced by newer hardware?
I now have Linux and Windows running side by side in two datacentres - both have only been down (the machines rather than than the connections) for security updates* in those four months - which I don't count as downtime since I choose when to reboot.
* - I do keep track of these: The Debian based Linux server has been down three times for kernel updates and the Windows 2003 server has been down once for an update but I didn't note down what it was.
PermalinkAnother easy question!
Firstly, what type of screen size are you looking for?
There are two types you can look at - the current working area, basically the area a maximised application will fill if it is polite, and the physical screen which expands from the top row of pixels to the bottom of the start bar on a standard setup.
Thankfully the Screen class offers up both of these as properties, so you can easily:
int height = Screen.PrimaryScreen.Bounds.Height;
int width = Screen.PrimaryScreen.Bounds.Width;
To get the exact, complete screen size (it may be better to handle this as a Drawing.Rectactle as that is how Bounds is typed, however for ease of explanation this is how I will do it here).
And, just as easily you can do:
int height = Screen.PrimaryScreen.WorkingArea.Height;
int width = Screen.PrimaryScreen.WorkingArea.Width;To get the total usable space for a friendly application.
Please don't use this to work out how big you need to make your always on top application so you can obscure the start menu - that is extremely annoying ;)
PermalinkThis is a quick and easy one for anyone else trying to send mail using ASP.NET.
First, add the using statement for the appropriate namespace:
using
System.Web.Mail;Then, create a MailMessage object:
MailMessage m = new MailMessage();
m.From = "simon@nullifynetwork.com";
m.Subject = "A demo message";
m.Body = "This is the body\n\n-Simon";
m.To = "you@yourplace.com";
And then, finally - send it using the static method off SmtpMail:
SmtpMail.Send(m);
Another example of why .NET rocks, what used to be an annoyingly complex task is now suddenly relegated to being easy as anything...
(This article is to make up for this monster article which discusses opening file handles on physical devices...)
PermalinkYes, the wisptis.exe file is legitimate - it is part of the Windows Journal Viewer and you probably installed it through Windows Update.
It's related to the tablet PC architecture.
PermalinkSo Robert made another "RSS is the ultimate solution" post and almost everyone jumped on it like rabid dogs. Me included...
I have taken particular offense (not really the right word, as I greatly respect much of what Robert brings to the surface, and his opinions are usually fairly good - a healthy discussion is also nothing to get angry about!) at a reply to my comment there:
"It's also a way of getting the content itself delivered and stored on my computer."
This is a fairly annoying and completely false assumption regarding RSS.
The concept of the content being delivered to you is an excellent one, however this is NOT what RSS does. RSS is a simple XML file (or webservice) sitting on the web waiting to be collected by your computer.
It does not tell you when it is updated. It doesn't send itself down the line to you. It isn't even distributed as far as your ISP's servers like E-Mail/Usenet is!
RSS is being used to solve a problem because it wasn't designed from the ground up as a syndication format - it was designed as a machine readable version of a site, hosted in the same way as the site itself.
A true solution to the problem would be to send the appropriate part of the RSS file down the line via some active means - even if it's just as far as the ISP's servers, this is a much more logical solution.
It has a plethora of benefits just a couple of which are instant or near instant updating of your readers with what they're interested in and far less bandwidth usage in all scenarios at all ends.
The technology already exists with MSN Alerts, MSN/AIM/Yahoo/ICQ/Jabber and dare I say it, E-Mail (shame this has been spoilt by the spammers and is useless for its purpose). Why can't we use one of these instead of making a square solution fit a round problem?
RSS frustrates me for what it's being turned into, and for how that is being done.
Permalink 2 CommentsWant to access a physical device (COM port, tape drive, LPT port, anything...) using C# .net?
You can't. Not natively anyway:
FileStream fs = File.Open("
\\\\.\\COM1", FileMode.Open, FileAccess.ReadWrite, FileShare.None);Happily errors out saying you can't use the \\.\ format with a FileStream (\\.\ becomes \\\\.\\ when you escape the backspaces with more backspaces).
FileStream does however allow opening a handle, so all is not lost, you can simply use the format:
FileStream fs =
new FileStream(handle, FileAccess.ReadWrite);After opening the handle using a CreateFile API call. To use this API call you need to platform invoke it, which is easily done once you look at the docs for it:
[DllImport("Kernel32.dll")]
static extern IntPtr CreateFile(string filename, [MarshalAs(UnmanagedType.U4)]FileAccess fileaccess, [MarshalAs(UnmanagedType.U4)]FileShare fileshare, int securityattributes, [MarshalAs(UnmanagedType.U4)]FileMode creationdisposition, int flags, IntPtr template);
(http://www.pinvoke.net/ is a great place to cheat)
You can then get handle (note that rather than defining the actual handle variable I'm going to put the CreateFile call inside the FileStream constructor - you could instead do InPtr handle = CreateFile() etc) by using CreateFile:
FileStream fs = new FileStream(CreateFile("\\\\.\\COM1", FileAccess.ReadWrite, FileShare.ReadWrite, 0, FileMode.Create, 0, IntPtr.Zero), FileAccess.ReadWrite);
First timers should remember to update their using statements, one for the FileStream, and one for the [DllImport]:
using System.IO;
using System.Runtime.InteropServices;
This one's an old one. It has been floating around in the blogging community for ages, and I figured I would just plain ignore it because the arguments both ways are fairly petty from my perspective. I don't like that method of syndication at all - and would much prefer a push medium for it, like msn alerts or icq/jabber can be made to do.
But someone has finally asked me if I can add an Atom feed.
This is a little annoying, since I already have an RSS feed, but I like to satisfy people so I busily go to look at the atom specification. It was far better though out than RSS for the job it's doing and it supports many more features. If I was implementing the syndication features of my site again I'd choose atom.
But I have no intention of doing it for the moment, there's simply no practical benefit to it over rss - they are simple xml versions of content that is available through other means - I'm really tempted to make my own spec for a syndication format and see if a similar contest occurs...
Lets call it Stupidly Simple Syndication
<Feed>
<Name>Feed name</Name>
<Home>URL</Home>
<Pinger>Address of XML webservice that allows you to define a url, ip and port, icq number, jabber address, passport or email address to call back when this feed is updated</Pinger>
<Article>
<Date>UTC date and time</Date>
<Link>Link back to the article</Link>
<Author>Author contact details or name</Author>
<Subject>Subject</Subject>
<Category>Optional category of article</Category>
<Extensions>Somewhere people can put anything extra about articles</Extensions>
<Content>The article</Content>
<Comments>
<Comment>
<Date>UTC date and time</Date>
<Author>Author contact details or name</Author>
<Subject>Subject</Subject>
<Extensions>Again, optional stuff</Extensions>
<Content>The comment</Content>
</Comment>
</Comments>
</Article>
</Feed>
We will rely on the existing HTTP headers to define when it was updated, when to fetch another one, etc. since we don't want to waste bandwidth.
We will also not worry about implementing shedloads of features most people won't care about in the base implementation, instead we will allow the use of extensions. Setting up a webservice at a reliable url on the net allowing people/aggregators to pull out a description of the extensions used in a feed (ie - what format data is in there, why, what's a human name for it, is it for a machine or a reader, etc.) and anyone to register one.
This will permit it to have more features than either RSS or ATOM, whilst also being small, perfectly logical, and stupidly simple to begin with.
PermalinkSo, I had come up with a way to do double buffering before using a backbuffer and flipping it to the front for a simple game I wrote as a test.
I have just noticed there's a Control.SetStyle method:
this.SetStyle(ControlStyles.DoubleBuffer | ControlStyles.UserPaint | ControlStyles.AllPaintingInWmPaint, true);
this.UpdateStyles();
Executing this in the forms constructor will turn on double buffering the correct way.
PermalinkThree years to the day yesterday, at 12pm I started full time work at unnamedWorkplace when I should have gone on study leave for my exams. 12:00pm today I am 24 hours free with a stack of work, list of projects, bunch of supportive friends and no worries for the moment.
My departure from unnamedWorkplace was swifter than I expected after giving in my notice, but overall this is probably for the best... I have lots of ideas for the short term, but in the long term I'm open to suggestions, or whatever turns my way.
Now to build my own future...
Permalink 1 CommentsThis is a rant, one of those almighty work related rants that result in Bad Things usually. But it needs to be said.
So I go to unnamedWorkplace every day, in and out and support the 2500 ish users there. I do more than my hours and make sure of it after I was complained about leaving early one day (after coming in early) even though I take none of the legally required breaks and just take the time at lunchbreak I need to eat.
I put in as much effort as I can. I am overworked, yet I feel like I haven't exerted myself mentally. The problems are always small, simple issues; relating to configuration, data extraction, hardware problems, accidents or downright stupidity on the part of the users.
The points on my appraisel completed, are ones I had to complete - all training was paid for by me, all self improvement driven by me. The unnamedWorkplace has failed to complete all of its points, including taking another appraisel, I believe it was due December 2003.
On the whole, the only reasons I have not resigned are the sallary and lack of a replacement for the moment; and my other colleagues across all departments. My friends are steadily leaving too - another four people I work with and have known well for many years have announced they are leaving, and the beaurocracy and inefficiency is steadily increasing.
So go on, make my day. Eliminate one of the reasons for me to stay: If you have an interesting programming or complicated support job let me know, if I can't do it now I will adapt. Fast. I'd even work for free for a bit as a trial (subject to contract of guaranteed employment or payment for time spent!).
Permalink 7 CommentsA friend of mine has made a post to his blog (http://www.illegalexception.com/content.php?id=102) about web services been bad for security. I don't see it that way - I see them as exactly the same as any other web based application or script that's exposed to the Internet and no more insecure.
That's not to say they aren't all insecure in some way, but he's concerned about the security of the client when a web service runs on the server and provides only an XML interface for data exchange.
I can't understand why a virus, trojan, or idiot user would install a webserver, configure a scripting language (Java servlets, PHP, ASP.NET, what have you...) then advertise a web service that will run with fairly limited rights (ie - the rights of the scripting language, which can't be root on *nix and is commonly INET_yourcomputer on Windows).
It would be far easier for a virus to simply down the local firewall then open a port - and it would have more power once it was done.
Web services simply take the human interface out of web applications, allowing an application to directly access one as if it were a local module of code - IE - the amazon web services allow you to search for products on the amazon site, and get back a list of objects in your application.
PermalinkSo someone e-mailed to ask me why I used as to cast my object:
IHiThere asm = o as IHiThere;
if (asm != null)
{
MessageBox.Show(asm.Hi());
}
else
{
MessageBox.Show("Failed to make asm = o");
}
Rather than:
IHiThere asm = (IHiThere)o;
When it is neater.
Well, there is a simple reason: This is because the as operator doesn't throw an exception when it fails but instead fills the variable with null. The check if the value was null checked if the code worked or not.
Note that in the real world you will want exception handling around the whole block, incase the user selects the wrong type of dll, or access to it is denied, or... well, you get the picture. This means you can freely use brackets to cast it - but this is in my opinion a more elegant method of doing something where you want to know if it succeeded or failed.
Update in 2009:
I would just like to clarify that I was trying to make the point that you should use the as keyword when it's something you expect not to work but don't want to use the is keyword!
PermalinkSo, I'm playing with reflection with the intention of making a plugin system for future use and looking at the obscenely complex articles on the net that don't cover anything even remotely like what I want to do. Which is have an object I didn't write, and be able to .DoSomething with it rather than have four lines of garbage to just run a static method. I wanted to be able to use classes I hadn't referenced at design time, just as if I had. Obviously they need to follow my interface definition, but that's a small price to pay.
So I eventually give up and go back to the docs and play around for a bit, eventually getting this ludicrously simple method working:
OpenFileDialog openasm = new OpenFileDialog();
if (openasm.ShowDialog() == DialogResult.OK)
{
Assembly testasm = Assembly.LoadFrom(openasm.FileName);
Type[] asmtypes = testasm.GetTypes();
foreach (Type t in asmtypes)
{
if (t.IsClass & t.GetInterface("IHiThere")!=null)
{
object o = testasm.CreateInstance(t.FullName);
IHiThere asm = o as IHiThere;
if (asm != null)
{
MessageBox.Show(asm.Hi());
}
else
{
MessageBox.Show("Failed to make asm = o");
}
}
}
}
A quick rundown, that's:
Load the assembly you want to look at:
Assembly testasm = Assembly.LoadFrom("filename.dll");
Get a list of the types of objects in it:
Type[] asmtypes = testasm.GetTypes();
Loop through it, and for each class that implements your chosen shared interface* create it as an object:
object o = testasm.CreateInstance(t.FullName);
Then cast it to your interface:
IHiThere asm = o as IHiThere;
Creating it as a local object you can use just like normal:
MessageBox.Show(asm.Hi());
* - Note that the interface in question here looked like:
public interface IHiThere
{
string Hi();
}
And was referenced by both the 'plugi' and the 'host' application.
The plugin side was a simple class that implemented the IHiThere interface, and returned "Hellow world from the plugin" as a string in the Hi method:
public class Class1 : IHiThere
{
public Class1()
{
}
public string Hi()
{
return "Hello World - from the plugin";
}
}
This is a bit of a rant, but still - might help someone also plagued with the same problem.
I'm doing several projects at the moment, and finding that templating in ASP.NET is non-existant. I know it's going to be fixed with the new version in 2005 - but still, I don't want to wait.
So when making a page with a consistent layout you have three choices:
- Generate all content for the page and feed it to the client, ignore all the object based capabilities of asp.net and use it like PHP or Java server pages.
- Use copious literals to import your header, footer and menu from someplace or auto-generate them at run time. Again loose any nifty advantages asp.net had over the others in the process - but keep them for the main content
- Output the page as XML then format it using an XSLT.
At the moment I've gone with the literals - it's easiest whilst still being asp.net rather than c# generating html and sending it to a client.
But what did Microsoft expect us to do? This is just downright silly...
PermalinkUpdate: If you work for Maindec, go away and research this yourself. My previous manager was certain that you already knew how and didn't want my help before I resigned yet I'm getting repeated hits from your domain, so obviously what was meant was 'you know how to use a search engine'.
Someone hit this site with a referrer searching for how to convert from MDaemon to Exchange - something I'm casually thinking about every time I have to change something user related on our MDaemon server at work. MDaemon is technically fine at handling lots of users (although a bit slow without referential storage). But the user interface isn't suited to more than 500 users.
It's either Exchange or Exim and Courier-IMAP - which is a nice quick migration if you use Maildir's. (HINT: To convert from MDaemo's mail format to Maildir you simply need to copy the messages into the new folder of each maildir, then convert them to have unix carriage returns - you can do this easily with a three line shell script in bash on Linux)
With converting to Exchange, I think you would have to use the exchange migration tool that comes with Exchange 2003. This will allow you to connect over IMAP and fetch the messages. This will take a CONSIDERABLE time, but I haven't looked into exchanges API - it is likely fairly easy to bulk import the mail much quicker than via IMAP. I'll investigate this when I get a chance!
The easiest path to take is this:
- Set up the Exchange server, with all users, etc.
- Configure the Exchange server to recieve all mail
- Rename the MDaemon servers domain to be something else
- Notify all users to use the Exchange server and configure the machines/accounts/profiles of all users to use the new exchange server
- Tell the users they can access their old mail and send fine from the MDaemon system - but will only recieve mail on exchange.
- Migrate anyone that complains, and if you have lots of time free (cpu wise) try to migrate everything.
This will get your Exchange system up and running as quickly as possible - and fielding the queries from people will take less time than migrating the data in cases where there's considerable data in place. You'll be surprised that only a few people will want all their old mail in the same place as their new mail - mail is time dependant and eventually it will cycle over.
This does require that you leave the MDaemon system running for a year or so - but use of the system will decrease as time passes by, and when it reaches zero in a month you can back up the data and reuse the physical hardware.
Permalink 1 CommentsThis makes me very happy - it loads quicker than visual studio and has a few of the features I like from visual studio in it. It also allows you to highlight the current line - very handy in a wordwrapped document!
Omar Shahine at Microsoft mentioned it, and also covers how to replace notepad the correct way.
PermalinkI'm looking for something suited to pair programming but online and with simultaneous data entry capabilities. So both people have Visual Studio, both see the same code. One types in one place another types in another and they can each see (assuming they're working on the same file, and the same place in that file) each others typing in real time. This would allow for you to help another programmer. They say two heads are better than one...
That or if anyone has any idea how you can easily do the user interface to such a thing so I can build one myself. I was tempted to use accessibility to read the contents of a window then remoting to send it but this fails on the actual display of the entered data aspect. It adds a major disconnect to have it in a seperate window.
And I don't want to reinvent the wheel and completely write a multiline, multiuser edit box by hand. Not yet anyway... Permalink 6 Comments
I've been thinking, how do you get around telco lockin?
You can't - well, not easily. At least, not till there's a wireless mesh covering the whole world.
This is what the people at consume are aiming to get. I think the ham radio operators got it right when they tackled the problem, which puts consume on the right track - but we need a longer range wireless medium to solve the problem.
Now, 3g, gsm, and others can solve the problem of range - but they're also all relatively slow in performance. Ideal for keeping a continuous link, for chatting, for mail if you don't mind waiting - for voice services even.
So, what service covers the middle ground? I don't particularly want a multi-billion dollar license just to provide wireless service to my peers. I don't need a range in the kilometres (although that'd be handy!).
PermalinkOkay so I need to know a bit of Java and be able to build something if needed to help a friend so figured I should install the stuff to get it going.
Now, here's the first of not many plusses over .NET. I installed Eclipse by unzipping the archive and running it with an appropriate SDK installed.
It ran. I was impressed. Mostly by:
- The fact it wasn't as slow as treacle like all over Java IDE's I've had the dubious pleasure of trying out.
- The fact that it was obviously Visual Studio .NET with a few minor improvements like a most excellent colouring of the current line slightly different so you knew where you were even with wordwrap and/or a long line. Refactoring and code templates like what is coming out in Whidbey/Visual Studio .NET 2005 was also already in it and working well.
- My java app compiled and ran - the only difference between it and the equivalent C# app? For some stupid reason Java's ArrayList is in the java.utils namespace rather than a collections namespace.
- Eclipse looks correct on Windows XP. WHAT I hear you yell... Well, it's true. Visual Studio looks like it's on 2000 even if you change the theme, it's just poorer integration.
Now for the negatives I've noticed so far just playing around:
- No foreach on objects. This one is really getting to me. For just does not cut it!!!
- Threading doesn't use callbacks - you have to build a new thread class based on the parent class of Thread. Seems somewhat of a disconnect from keeping the code nice and modular.
- The string type is capitalised. Yes, I know this is petty.
- C# code looks nicer: Getters and setters are more neat and tidy.
- Where is delegation in Java? It just seems to be... missing.
- Interfaces seem to have been thought out more in C# - how do you prevent one being run if the object is addressed as its native type?
- Where are enums in Java? Also... absent without leave.
- I can't seem to find struct's either - how to you make a high speed primitive type?
- Where are the overloading features again? I can't find mention of most... Operator overloading for example.
- No versioned GAC.
- No attributes for methods.
All this is ignoring the multi-language capability of .NET, and the 'interesting' model of page generation of ASP.NET where objects exist between calls and
Permalink 3 CommentsHmm, lots of people out there are searching for Jen Frickell on Google and mysteriously getting to my site because I mentioned her a while back.
The site you're looking for is over there, not here, although she doesn't update as much as she used to, bar special occasions - like April fools day...
PermalinkHere's a little something that took a couple of hours to write, feedback is as always appreciated! As I've already been asked: this is all GDI based, no DirectX... Graphics for it would be appreciated!
Anyway, click here to run GravCave from my server, you need the dot net framework - available from windows update, or I expect it will run okay under mono. If you wish you can right click and save target as to your local machine - it's 40kb and will run from anywhere.
Another .NET game in the same vein is Chris Sells' Wahoo. This came about as I was curious why dot net based games were't slowly appearing yet, so thought I'd see how difficult it was to code a game in: turns out with C# it's much easier than many other languages.
I assume when people realise that they CAN use DirectX with an app that is loaded directly from the net, they'll start using it.
UPDATE: Source code is available on this page on my site
PermalinkEver wondered how to double buffer with a Graphics object so your GDI+ based game/control doesn't flicker annoyingly?
Me too. There's probably a built in method that's easier, but this is how I managed to get it to work smoothly, it's nice and simple and allows you to draw anywhere that offers up the normal CreateGraphics method.
First, set up a bitmap to act as your backbuffer:
Bitmap BackBuffer = new Bitmap(this.ClientSize.Width,this.ClientSize.Height);
Graphics DrawingArea = Graphics.FromImage(BackBuffer);
Next, you want to draw to your graphics object as normal, so DrawingArea.Clear(Color.Black); and such.
Once you've completed drawing the object that you want to smoothly move, simply draw the pre-rendered bitmap over the top of the Graphics object you want to update:
Graphics Viewable = this.CreateGraphics();
Viewable.DrawImageUnscaled(BackBuffer, 0, 0);
You can also use other techniques to increase the performance, such as reusing the backbuffer by defining it in the class you're using it in - this means .NET won't need to recreate it repeatedly.
PermalinkOkay so I was just wondering why Kunal Das' OutlookMT looked very much like the idea I had for solving the problem, until I find this post whilst searching for a way around the annoying security dialog you get when accessing Outlook from C#:
http://blogs.officezealot.com/Kunal/archives/000503.html
It looks like a suggestion I made on Scoble's site about how I would access Outlook to enable blog integration was the initial inspiration for OutlookMT's solution to Scoble's problem.
I guess this blogging thing really does work...
PermalinkIf your validation isn't working in Asp.net after deploying to a webserver with multiple virtual hosts you might find you need to copy the aspnet_client directory from the default site to the affected site to get the client-side validation working.
A good reason to always do server side validation!
PermalinkThis is my first attempt at an instructional article, so opinions on quality would be great! Let me know if I made any mistakes too...
It's mainly for all those like Robert Scoble who would like to be able to drag and drop an item to a folder in their Outlook and post it instantly to their Blog, but it also covers web services and talking to Outlook.
Accessing Outlook
The first requirement is to be able to access Outlook. For those with Outlook 2003 and XP this is relatively easy, thanks to .Net and Microsoft shipping an appropriate assembly with Office. To install the Office 2003 assembly, you should run the office install and choose .NET Programmability Support.
You might need to use the command prompt to copy Microsoft.Office.Interop.Outlook.dll out of the GAC after installing it so you can add a reference to it, if you can add it as a reference otherwise do so and let me know how! The Visual Studio add reference dialog doesn't seem to list items in the GAC...
Add an appropriate using clause:
Then you should be able to instantiate an Outlook object and make requests of it:
Outlook.Application app = new Outlook.ApplicationClass();
Outlook.NameSpace NS = app.GetNamespace("MAPI");
Outlook.MAPIFolder inboxFld = NS.GetDefaultFolder(Outlook.OlDefaultFolders.olFolderInbox);
This will give you access to inboxFld, which will allow you to iterate through the contents of the inbox! You can also change this to iterate through notes, or through calendar entries, tasks, etc. as you want.
For example, to iterate through your mail you can do:
Console.WriteLine(t.Subject);
}
To write out all the subjects on the console. The only annoying thing will be you need to say yes to a security dialog when you access mail items - I'm working on getting around this, it doesn't happen for tasks or notes, etc.
Once you are able to access Outlook, your next objective is to post data to your weblog. You can avoid duplicates through one of two ways:
- Keep track of what has been posted by maintaining an ArrayList of articles on your blog and checking before trying to post one.
- Keep track of what has been posted by changing something in the MailItem's - e.g. - set or clear a flag.
The first method requires keeping a list synchronised with the blog, the second is quickest and easiest, but wouldn't be suited with multiple people possibly posting things.
Posting to your blog
Obviously everyone is using different software to manage their blog. I can't give an example of every single method, however the simplest from a programmers perspective is if you can access the database of your blog via a webservice.
Building a webservice
Google can supply many examples and tutorials, however an example of doing this is fairly simple.
Choose to add a new webservice to your site, or create an entirely independant project and call it something suitable - ours will be blog because it's an example.
Firstly, you will need to add a few more items to your using list, so you can do XML serialisation of structures and objects. I will assume your database is MS SQL Server too, so ensure the following are listed in addition to the defaults for a webservice (I forget what they are):
using System.Web.Services.Protocols;
You want to be as object oriented as possible when building your webservice, so you should define a NewsItem structure to pass back and forth, you can adjust this to include whatever you need to store in an article:
{
public int id;
public string topic;
public string subject;
public string postedby;
public DateTime postedat;
public string content;
}
This will allow you to reference rows in your database as objects, a simple organisational benefit that crosses over and permits easy use of methods of the webservice without passing a lot of parameters. It also allows you to add groups of entries to an ArrayList, which is a big benefit (although there is a problem converting from an object transferred by a webservice and an ArrayList, if you ever do this you will need to iterate through the object and add the entries back to an ArrayList - .net does not support converting from an object[] to an ArrayList).
You can then build your method for adding the article to the database. I have used the database on my blog as an example, you will obviously need to change the insert statement and connection string to fit your situation. There is also no exception handling, ideally you should enclose the opening of the connection and the executing of the query in Try Catch blocks.
Note that the XmlInclude for the NewsItem struct is listed, this allows the webservice to accept a newsitem given as a parameter - otherwise if would not know to serialise the structure.
[WebMethod]
[XmlInclude(typeof(NewsItem))]
public void AddArticle(NewsItem newarticle)
{
SqlConnection sqlcn = new SqlConnection("Data Source=(local);" +
"Initial Catalog=NullifyDB;" +
"Integrated Security=SSPI");
sqlcn.Open();
SqlCommand sqlcmd = new SqlCommand("INSERT INTO newsarticle (subject, topic, content, uid) VALUES (@subject, @topic, @content, @postedby);", sqlcn);
sqlcmd.Parameters.Add("@subject", newarticle.subject);
sqlcmd.Parameters.Add("@topic", newarticle.topic);
sqlcmd.Parameters.Add("@content", newarticle.content);
sqlcmd.Parameters.Add("@postedby", 253);
sqlcmd.ExecuteNonQuery();
sqlcn.Close();
}
You should then provide additional methods for anything else you would want to do, such as listing articles, deleting articles, and editing. For Outlook integration you really only need this method.
Accessing the webservice
Once the web service is up and working, you need to create a web reference to the webservice, this is done in visual studio by right clicking the references box and choosing add web reference. Lets say there's one at http://webservices.nullify.net/blog.asmx
When you add a web reference Visual Studio will automatically produce a wrapping class that will allow you to easily instantiate the web service as a local object, without worrying about any of the underlying technology. (I'll only cover synchronous calls here, otherwise this will turn into a full fledged book...)
To access the above web service, you would simply define it as a new object:
net.nullify.webservices.Blog blog = new net.nullify.webservices.Blog();
And you would define our NewsItem scructure that we defined in the webservice:
net.nullify.webservices.NewsItem article = new net.nullify.webservices.NewsItem();
This will allow you to now call methods of the blog object, which will execute directly on your web server, with all the rights of a normal asp.net page - including the ability to insert articles into your database!
Using our imaginary webservice, rather than writing the subject for each MailItem to the console, you can post them to your blog:
article.subject = t.Subject;
article.content = t.Body;
article.topic = "OutlookPost";
blog.AddArticle(article);
(Note, this is assuming your webservice has no security, or is protected by asp.net/IIS' own security!)
I hope this post helps someone!
public struct NewsItem
using System.Xml.Serialization;
using System.Web.Services.Description;
using System.Web.Services;
using System.Data.Common;
using System.Data.SqlTypes;
using System.Data.SqlClient;
foreach (Outlook.MailItem t in inboxFld.Items)
{
using Outlook = Microsoft.Office.Interop.Outlook;
(This article has been truncated due to migration to a new database, apologies! I hope what is here helps and if you have questions there are copies around on the web of this article.)
PermalinkI finally understand.
The reason I've been unable to write good documentation all this time is who has been reading it. I write code that describes how to do something to a computer. That documentation must be excellent syntactically, all encompassing and as flawless as possible. It must also be complicated as the compiler/interpreter is generally fairly stupid and needs intructions for every step.
I have a tendancy to take that over when documenting the code, what I really need to do is say "This does x" rather than "This does y to z in order to get x to be the desired value, but has to take into account a, b, and c factors".
I finally understand - document simply and briefly to document well...
PermalinkDo you have an idea for a piece of software that you personally would like?
A tool that would help you in your day to day use of a computer? Something that would be neat on your smartphone? An application to store/retrieve a particular type of information on a pocket pc?
Something that solves a problem in your classroom/computer lab/school/university/office/shop floor?
A web site that needs to do something really special?
If you want it more than you want to sell it, let me know your idea. I am willing to solve interesting problems free of charge so long as I keep full rights to resell them! FREE development. You/your company/your school/your university get full rights to keep it and if you so desire distribute a marked copy so long as you don't charge for it I'm open to other relationships too such as sponsored open source, and complete development under contract - ideal if you need something like a website that can answer industry specific questions from your users, or that needs to solve a problem that won't sell to others. Or if you just want to keep your hands on it!
What do I get out of this? There is a chance I could get to build the next winzip.
What do you get out of this? Your problem is solved. Period.
What can you get out of a really good idea? A split of any profits!
Hopefully this business model will suit anyone, with any amount of money so long as there is a need or an idea, let me know your opinions.
I'm already working on one solution using this idea, and it seems to be working quite well for everyone involved.
PermalinkThe new version is written in C#, and although I've built it so the urls of everything are the same certain things have changed.
Therefore expect things to break a little... (RSS GUID's for one thing, the admin system, no more workdrive file storage for the moment, no comic management)
Workdrive will be reappearing completely rewritten in .NET in a short while, along with full PIM and Outlook integration.
Update: All done and live!
Another update: And the RSS feed now validates too... Permalink 4 Comments
I got sent to https://oca.microsoft.com/EN/Response.asp?SID=77 ("Error Caused by a Device Driver") which is completely useless.
During seperate testing on another machine, I found that this can also result in an immediate crash on login as the system attempts to play a sound.
Lets see how many people get sent here from google...
To workaround for this problem to prevent the system crashing is you need to go into the Sounds and Audio Devices control panel, then change the default devices for playback and sound recording to a present soundcard either in safe mode if you don't have access to the USB audio device, or before removing the device.
Now to find out how to actually submit more details for a microsoft bug report... A simple "What were you doing when this happened?" text box would probably help a ton on the oca.microsoft.com site. Permalink